As we continue our Openshift journey to get virtualization working, we have a vanilla node already setup and now we need to get the networking configured. The examples here are from Openshift 4.19.17.
Networking in OpenShift is conceptually two parts that connect. The first part is the host level networking; this is your CoreOS OpenShift host itself. Then there is how do the pods connect into that networking. Usually, the network connects through your network interface card (NIC), to the Container Networking Interface (CNI), then to your pod. Here we will be using a meta plugin that connects between the NIC and the CNI called Multus. Redhat has a good post about it.
Host Level Networking
This part of the networking stack is straight forward if you are used to Linux system networking, and it is setup the same way. Treat the CoreOS node like any other Linux system. The big decision to make in the beginning is how many interfaces you will have.
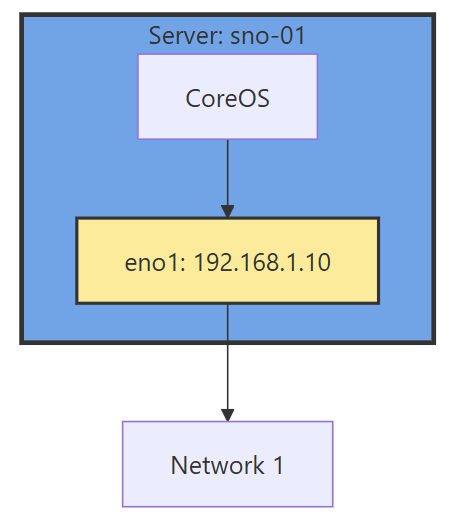
If you have 1 interface and plan on using virtualization, are you going to use VLANs? If so, then you may want to move the IP of the interface off of the primary interface and onto a VLAN sub interface. This moves the traffic from untagged to tagged traffic for your network infrastructure.
Another reason is there are bugs in the Mellanox firmware, mlx5e, where Mellanox 4 and 5 cards can think you are double VLAN encapsulating, and will start automatically stripping VLAN tags. The solution is to move all traffic to sub interfaces. You will get an error in your dmesg/journalctl of: mlx5e_fs_set_rx_mode_work:843:(pid 146): S-tagged traffic will be dropped while C-tag vlan stripping is enabled
With the interface moved, that frees us up to use it for other VLANs as well. If you deployed network settings via a MachineConfig, you would have to override them there.
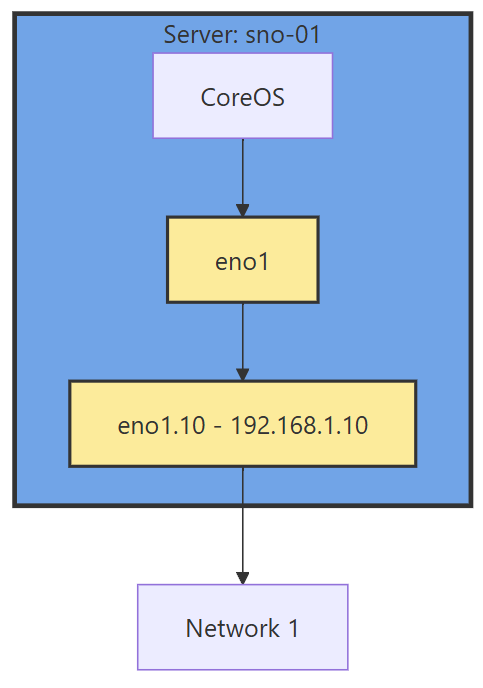
The rest of the configuration will be done via the NMState Operator and native Openshift.
NMState VLAN and Linux Bridge Setup
NMState is a Network Manager policy system. It allows you to set policies like you would in Windows Group Policy, or Puppet to tell each host how the network should be configured. You can filter down to specific hosts (I do that for testing, to only apply to 1 host) or deploy rules for your whole fleet assuming nodes are all configured the same way. It’s possible to use tags on your hosts to specify which rules go to which hosts.
NMState can also be used to configure port bonding and other network configurations you may need. After configuration, you get a screen that tells you the state of that policy on all the servers it applies to. Each policy sets one or more Network Manager configurations, if you have multiple NICs and want to configure all of them, you can do them in one policy, but it may be worth breaking the policies apart and having more granularity.
Another way to go about this section, is to SSH into each node, and use a tool such as nmtui to manually set the networking. I like NMState because I get a screen that shows all my networking is set correctly on each node, and updates to make sure it stays that way. I put an example below of setting up port bonding.
- Go to the OpenShift web console, if you need to setup OpenShift I suggest checking out either my SNO guide or HA Guide.
- Click Operators -> OperatorHub.
- Install NMState.
- Worth mentioning you can do all this with OKD, except NMState is very old, and hasn’t been updated in 5 years. Either NMState would need manually installed, or the interfaces would need manually created.
- Once installed, you will need to create an “instance” of NMState for it to activate.
- Then there will be new options under the Networking section on the left. We want NodeNetworkConfigurationPolicy. Here we create policies of how networking should be configured per host. This is like Group Policy or Puppet configurations.
- At the NodeNetworkConfigurationPolicy screen, click “Create” -> “With YAML”.
- I put some additional YAML files below under Additional NodeNetworkConfigurationPolicy YAMLs
- We need to create a new sub-interface off of our eno1 main interface for our new vlan, then we need to create a Linux Bridge off that interface for our VMs to attach to.
apiVersion: nmstate.io/v1
kind: NodeNetworkConfigurationPolicy
metadata:
name: vlan19-with-bridge <-- Change This
spec:
desiredState:
interfaces:
- name: eno1.19 <-- Change This
type: vlan
state: up
ipv4:
enabled: false
vlan:
base-iface: eno1
id: 19 <-- Change This
- name: br19 <-- Change This
type: linux-bridge
state: up
ipv4:
enabled: false
bridge:
options:
stp:
enabled: false
port:
- name: eno1.19 <-- Change This
vlan: {}
- Important things here:
- Change the 19s to whichever VLAN ID you want to use.
- “ipv4: enabled: false” says we want an interface here, but we are not giving it host level IP networking on our OpenShift node.
- Remove the <– Change This comments
- You MUST leave the “vlan: {}” at the end or it will not work, adding this tells it to leave vlan data how it is because we are processing via the kernel via sub interfaces.
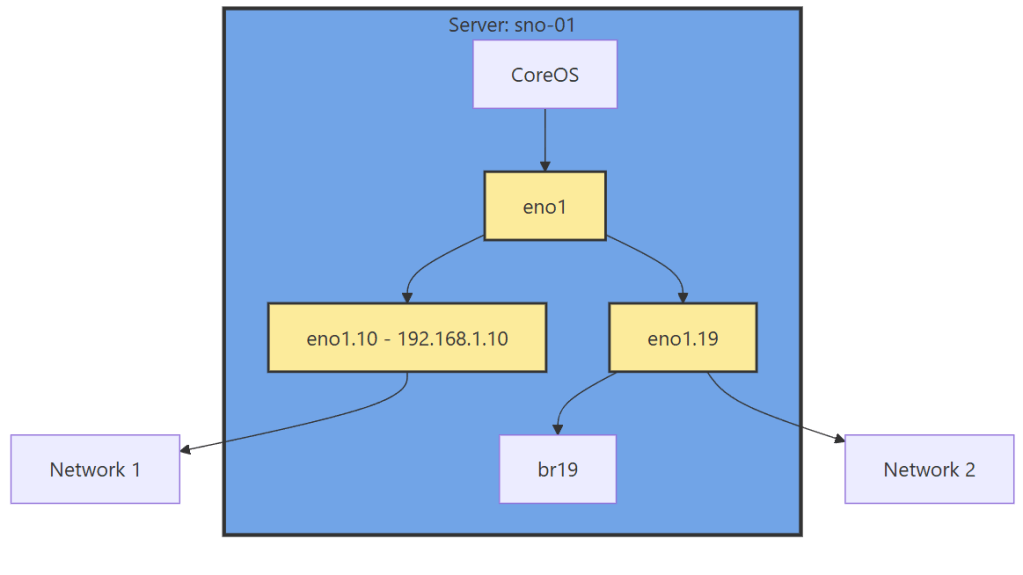
Now we have this configuration, with a secondary interface off of our NIC, and an internal Linux Bridge for the VMs.
The great thing about doing this configuration via NMState, it applies to all your nodes unless you put a filter in, and you get a centralized status about if each node could deploy the config.
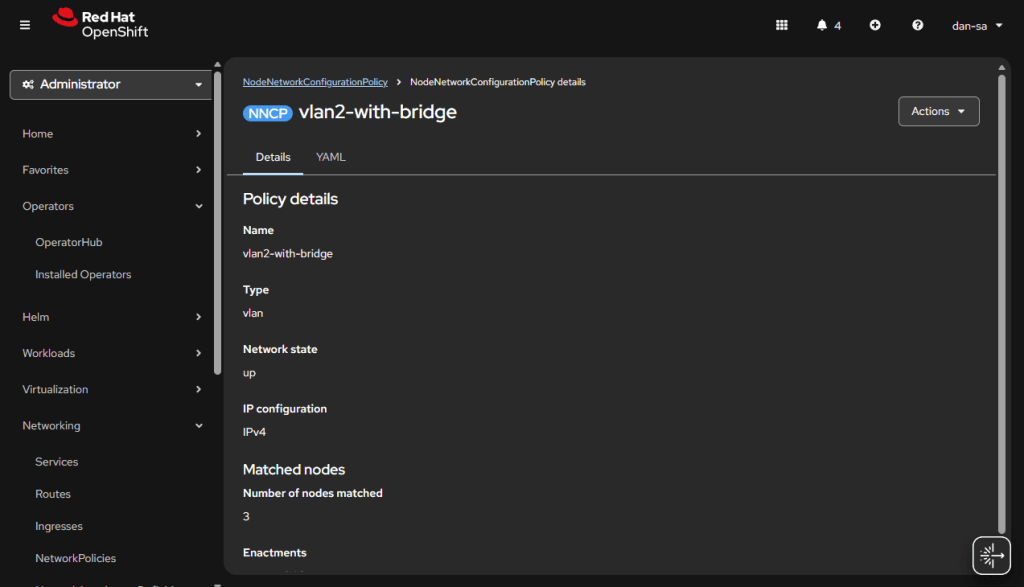
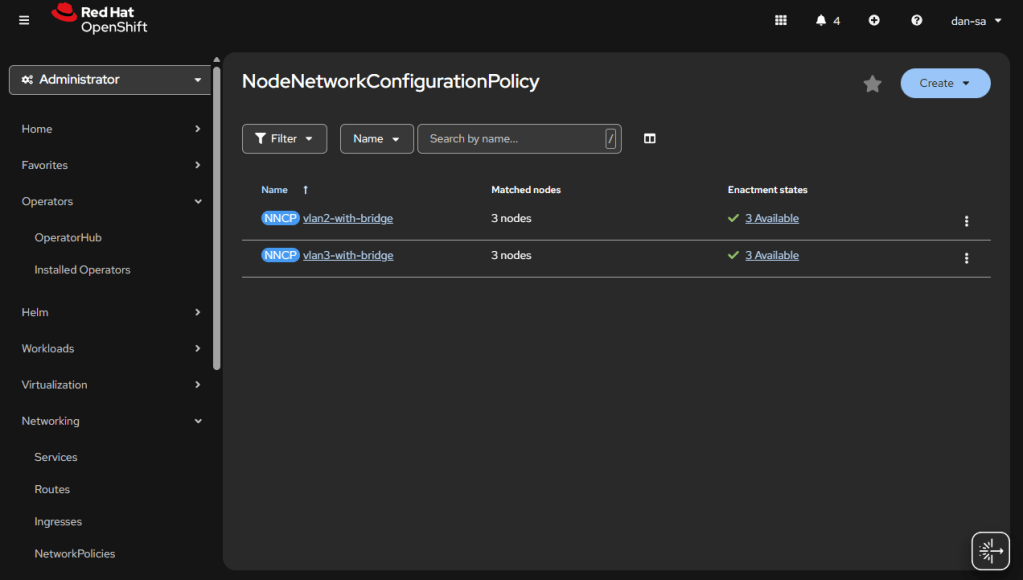
Here is an example from my Homelab, with slightly different VLAN IDs than we have been discussing. You can see all three nodes have successfully taken the configuration.
OpenShift VM Network Configuration
Kubernetes and OpenShift use Network Attachment Definitions (NADs) to configure rules of how pods can connect to host level networking or to the CNI. We have created the VLANs and Bridges we need on our host system, now we need to create Network Attachment Definitions to allow our VMs or other pods to attach to the Bridges.
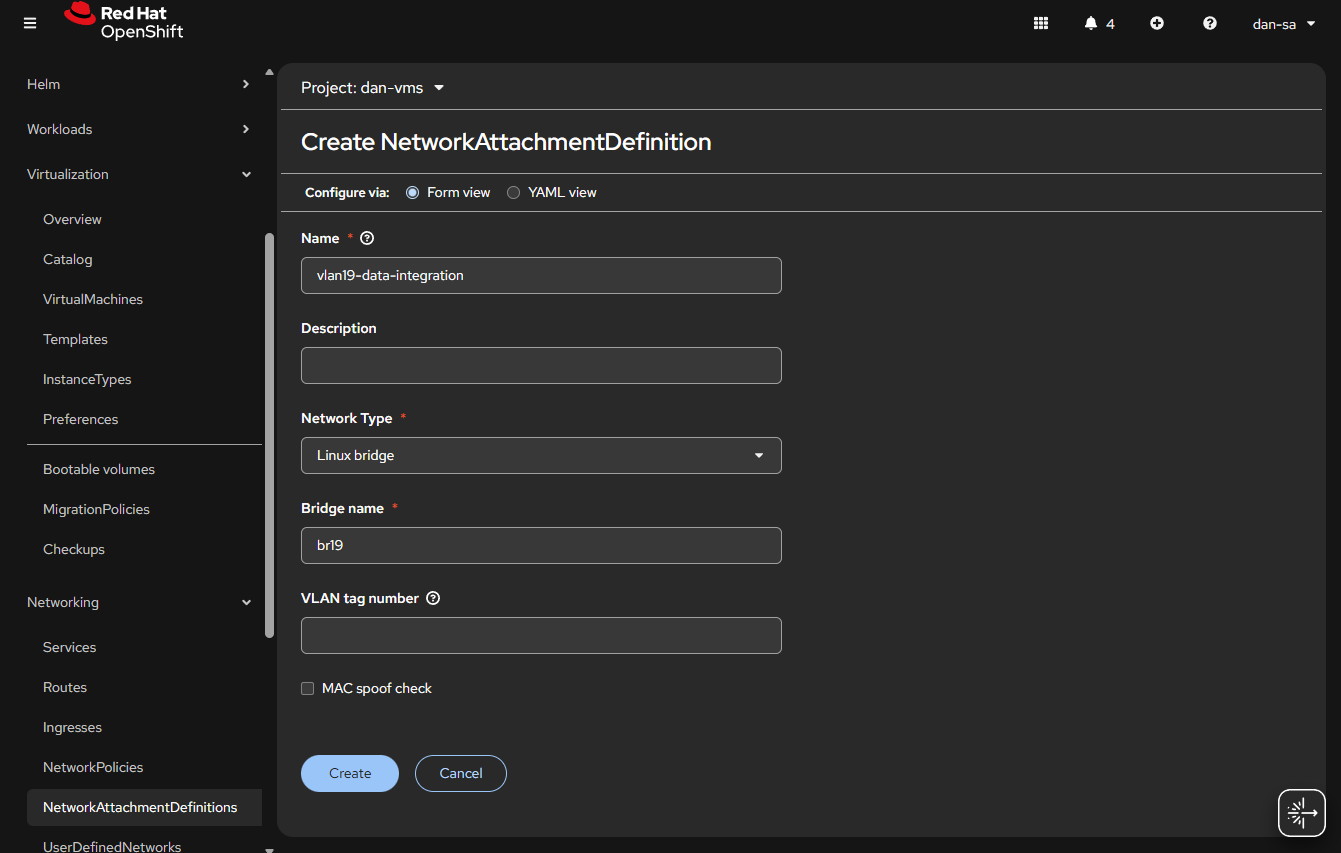
- Go to “Networking” -> “NetworkAttachmentDefinitions”.
- Click “Create NetworkAttachmentDefinition”
- This is easily done, and can be done via the interface or via YAML, first we will do via the UI then YAML.
- Before entering the name, make sure you are in the Project / Namespace you want to be in, NADs are Project / Namespace locked. This is nice because you can have different projects for different groups to have VMs and limit which networks they can go to.
- Name: This is what the VM Operator will select, make it easy to understand, I do “vlan#-purpose“, example: “vlan2-workstations”.
- Network Type: Linux Bridge.
- Bridge Name: what was set above, in that example “br19“, no quotes.
- VLAN tag number: Leave this blank, we are processing VLAN data at the kernel level not overlay.
- MAC spoof check: Do you want the MAC addresses checked on the line. This is a feature which allows the network admin to pin certain MAC addresses and only send traffic out to those allowed. I usually turn this off.
- Click “Create“
The alternative way to do a NAD is via YAML, here is an example block:
apiVersion: k8s.cni.cncf.io/v1
kind: NetworkAttachmentDefinition
metadata:
name: vlan19-data-integration
namespace: default
spec:
config: |-
{
"cniVersion": "0.3.1",
"name": "vlan19-data-integration",
"type": "bridge",
"bridge": "br19",
"ipam": {},
"macspoofchk": false,
"preserveDefaultVlan": false
}
You can verify the NAD was created successfully by checking the NetworkAttachmentDefinitions list. Your networking is ready now. Next post, we will discuss getting storage setup.
Additional NodeNetworkConfigurationPolicy YAMLs
NIC Bonding / Teaming
Use mode 4 (802.3ad/LACP) if your switch supports link aggregation; otherwise mode 1 (active-backup) is the safest fallback.
apiVersion: nmstate.io/v1
kind: NodeNetworkConfigurationPolicy
metadata:
name: bond0-config
spec:
desiredState:
interfaces:
- name: bond0
type: bond
state: up
ipv4:
enabled: false
link-aggregation:
# mode=1 active-backup
# mode=2 balance-xor
# mode=4 802.3ad
# mode=5 balance-tlb
# mode=6 balance-alb
mode: 802.3ad
options:
miimon: '140'
port:
- eno1
- eno2
Useful Links
https://github.com/k8snetworkplumbingwg/multus-cni/blob/master/docs/how-to-use.md
https://medium.com/@tcij1013/how-to-configure-bonded-vlan-interfaces-in-openshift-4-18-0bcc22f71200