I am going to start a series of posts of random ideas I have had but not had time to fully implement. The first in this series is a idea I have worked on about ~3 years ago (November 2019) for being able to audit a datacenter as well as map systems physicals location to their logical one in a network.
The core of the idea is to use cameras in a datacenter to see servers in the rack, these could be security cameras, then use that data to map out the datacenter and save the administrators time from having to manually preform these actions. The process begins by training a machine vision learning model on what a server looks like. Most of the time at work I am working with Dell servers so I thought that was a good starting point. To make the model generic enough I was just attempting to train it on what a 1U server looks like vs what a 2U server looks like.
At this point I needed A LOT of photos of servers with different lighting and angles. I took a bunch myself as a seed set of different racks I had, then I turned to the web. Where could I get a large assortment of photos of Dell servers in different configurations and lightings? The homelab section on reddit! People all the time post their setups at home and what they have. I went through and downloaded several hundreds photos of different peoples setups. Another place to get photos was from eBay where a lot of sellers put up photos of servers in different settings; the downside is that a lot of people reuse the same photos again and again. I don’t know if the internet has yet to figure out what the copyright rules of using photos from online to train a model.
I researched a bunch of different techniques and was playing around with OpenCV, but then found a tutorial that seemed to be in line with what I was looking to do. (This one is also good, and very similar material) I researched different image processing models, and played around with several.
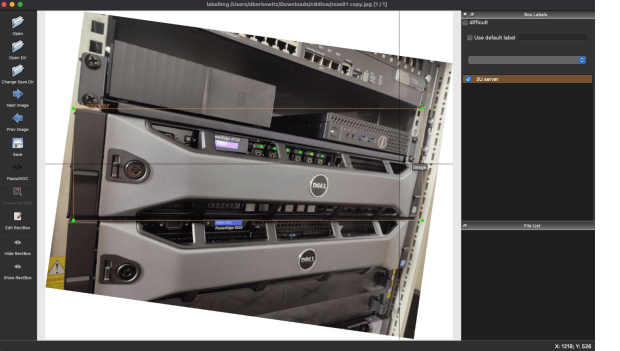
Now that I had the photos, I downloaded GitHub – tzutalin/labelImg: 🖍️ LabelImg is a graphical image annotation tool and label object bounding boxes in images. This is a tool where you go to each photo, select the item you are trying to learn, and label it. This took a while, its fully manual work. A lot of the photos from the web had multiple servers in the photo, and each one would need to be selected. This proved to be one of the more time consuming parts of the project. I had to manipulate the photos to allow the rectangular bounding boxes to be able to fit the servers, even when the photos are at weird angles.


I had to pick some of the photos to be the training set, than other photos to be the testing set. With that metadata ready and everything marked, I converted the final metadata from XML to CSV, using xml_to_csv.py provided at the above example repos. That was then fed into Tensorflow. The system I had to start with for this other than a laptop was a CentOS 7 server, this proved to be very annoying because some dependencies such as protobuf were not available at new enough versions and had to be custom compiled.

It was time to let the model run for a while and see what it could learn. Several important things were learnt in this process. First, if you have GPUs makes sure you have a Tensorflow that is compiled and ready to use them. The speed you speed you get with and without them is kind of crazy. Also, more RAM and GPU helps a lot speed up the process. At first I was playing with this on just a laptop, and that one didn’t have the GPU drivers for CUDA. This was taking DAYS to work on the model. Later I switched to using GPUs I had in a server, and this greatly increased the iteration cycle speed.

Off the bat it was able to get a decent percentage recognition of the servers in the photos I had presented it! I do think a lot of the photos I then tested it on were fairly ideal conditions, with good lighting and camera angle. This may give a better than real world experience with it working. To improve the model I can always find more photos and train it with more images. I was able to get the model to recognize about 80% of the servers in racks I showed it at this time. Another factor that could help in the future is the evolution of cameras. A lot of places are replacing 720p/1080P cameras with 4k cameras, the more resolution the system has to work with the better.
The next step I wanted to do was start matching physical location to logical. The idea behind this is, I can find regions in a photo or video where servers are, and each server through its iDrac/IPMI allows me to blink front chassis lights. So one host at a time I will have automation send the command to blink the front chassis lights, and perhaps some lights on the HDDs, then scan for which region in the photo has started to blink!
This is the idea I have slowly worked on for the last little while, I have prototypes of most of it working, but have not had a lot of time to put into it. The hope would be we could use existing cameras to get the footage we need to map existing datacenters we have. Then perhaps in the future port this system to something like Hololens, or Apple/Meta AR system. Once we have that mapping, now we can start to draw out the physical servers and their location in the world/racks on a webpage, and make it easier for people working in a datacenter to find boxes they need. Hopefully one day allowing for people to click a server on a webpage, and then connect into its controller without a human painstakingly going to each box and doing this mapping. Of course all of this is fixed by a team labeling each server, but where is the fun in that.
